
Uma dúvida comum entre os novatos em modelagem de dados é: melhor usar um modelo de dados completamente “flat” com apenas uma tabela ou investir tempo na construção de esquema em estrela adequado? Como Koen Verbeeck sempre diz: “Esquema estrela em tudo!!”.
O objetivo deste artigo é demonstrar que um relatório que uma tabela flat retorna números imprecisos, enquanto o uso de um esquema em estrela o transforma em um sistema analítico sólido.
O modelo de dados a ser analisado é simples. Uma empresa possui quatros salões de beleza: dois salões de beleza e dois de unhas. Os clientes visitam os salões e fornecem informações relevantes, como gênero e trabalho.
Você precisa criar um relatórios simples para analisar o número de visitas, dividas por gênero e função em um salão. No mesmo relatório, você deseja comparar as visitas do salão selecionado atualmente com o grupo ao qual ele pertence.
Em outras palavras, a pergunta a ser respondida é: como a distribuição de emprego e gênero entre os clientes de um determinado salão é comparada à média de todos os salões do mesmo tipo?
A fonte é uma única tabela, já contendo informações relevantes.
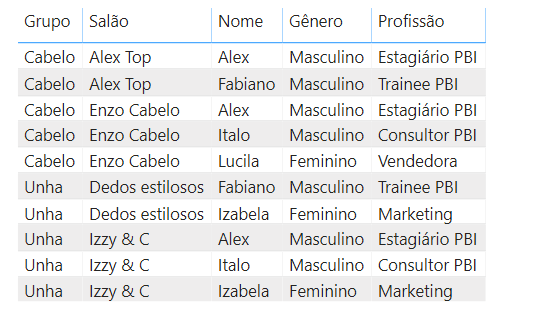
Como a tabela não contém nenhuma chave e todas as informações já existem, parece que não há necessidade de criar um modelo de dados sobre ela, ou seja, somente a tabela é suficiente.
De fato, um relatório com o número de visitas e sua porcentagem produz os resultados corretos.

No relatório, usamos essas medidas:
Visitas = COUNTROWS ( Visitas )
% Salao =
VAR NumVisitas = [# Visitas]
VAR NumVisitasMesmosalao =
CALCULATE (
[# Visitas];
REMOVEFILTERS ( Visitas );
VALUES ( Visitas[Salão] )
)
VAR Result = DIVIDE ( NumVisitas;NumVisitasMesmosalao )
RETURN Result
O % Salao atinge seu objetivo dividindo o número de visitas pelo número total das visitas no salão, independentemente de qualquer outro filtro.
O segundo passo prova ser muito mais desafiador. Queremos mostrar a distribuição de gêneros e empregos em todos os salões do mesmo grupo (cabelos x unhas).
O primeiro passo seria calcular quantas visitas houve no grupo ao qual o salão atual pertence. A medida a seguir não calcula os números certos, mesmo que pareça perfeitamente correta:
Grupo Visitas :=
CALCULATE(
[# Visitas];
REMOVEFILTERS ( 'Visitas'[Salão] );
VALUES ( 'Visitas'[Grupo] )
)
E o resultado:
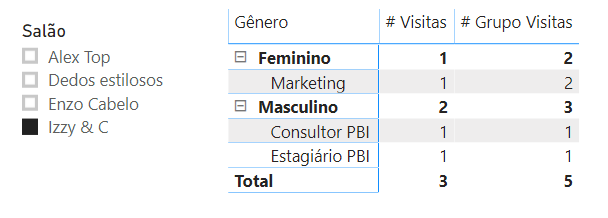
O relatório está claramente errado. Você pode verificar facilmente se os totais estão corretos. Houve três visitas masculinas no Izzy & C, de acordo com a tabela de origem exibida anteriormente, mas uma não é relatada em detalhes. Este exemplo, em sua simplicidade, está errado por dois motivos.
O primeiro motivo é o comportamento de “existência automática” – uma otimização interna do DAX que descrevemos em um artigo anterior. O Segundo motivo é a incapacidade do modelo de encontrar a relação entre grupo e salão no modelo de dados atual quando não há visitas.
Quando SUMMARIZECOLUMNS varre a tabela em um contexto de filtro com Izzy & C para Salão e Masculino para Gênero, ele mescla os dois filtros em um, impedindo a localização do trabalho ausente. Se você não estiver familiarizado com esse comportamento, sugerimos que você dê uma olhada no artigo mencionado acima, que explica mais profundamente o comportamento de “existência automática”.
Evitar o efeito da existência automática é simples: é necessário criar dimensões separadas para sexo e trabalho, para que um filtro em uma dimensão não afete as outras dimensões. Essa operação simples evita que a existência automática entre em ação.
Portanto, um primeiro passo (necessário, embora ainda não final) para solucionar o problema é criar duas dimensões: uma para o gênero e outra para o trabalho. O novo modelo se parece mais com um esquema em estrela.
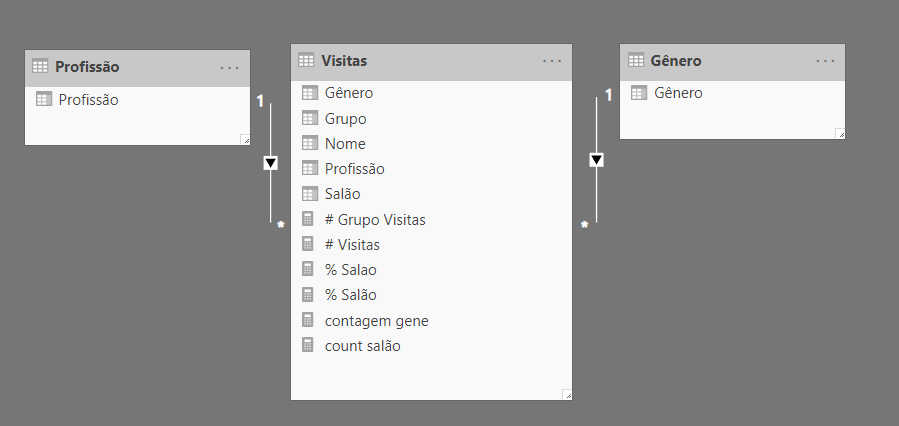
Em seguida, você precisa atualizar o fatiamento da matriz pelas colunas nas dimensões, em vez das colunas na tabela fato. No entanto, isso não é suficiente para resolver o problema, mesmo que tenhamos removido a questão da existência automática. De fato, os números parecem os mesmo – ainda estão errados.
Para garantir que a existência automática não seja mais um problema, você pode capturar a consulta executada pelo Power BI por meio do analisador de desempenho, limpá-la um pouco e veja como fica a aparência:
DEFINE
VAR __DS0FILTERTABLE =
TREATAS ( { "Izzy & C" }; 'VISITAS'[Salão] )
VAR __DM3FILTERTABLE =
TREATAS ( { "Feminino"; "Masculino" }; 'Gênero'[Gênero] )
EVALUATE
SUMMARIZECOLUMNS (
'Gênero'[Gênero];
'Profissão'[Profissão];
__DS0FILTERTABLE;
__DM3FILTERTABLE;
"VISITAS"; 'VISITAS'[# VISITAS];
"GRUPOVISITAS"; 'VISITAS'[# GRUPO VISITAS]
)
Como SUMMARIZECOLUMNS está agrupando e filtrando duas tabelas separadas, a existência automática não é ativada. Você pode verificar isso facilmente, executando duas versões ligeiramente modificadas dessa consulta. Introduzimos primeiro o IGNORE nas medidas para evitar a remoção de linhas em branco; em seguida, executamos o mesmo agrupamento de consultas primeiro pelas dimensões(sexo, profissão) e depois pelas colunas na tabela fato.
Esta é a consulta que agrupo as dimensões:
DEFINE
VAR __DS0FILTERTABLE =
TREATAS ( { "Izzy & C" }; 'VISITAS'[Salão] )
VAR __DM3FILTERTABLE =
TREATAS ( { "Feminino"; "Masculino" }; 'Gênero'[Gênero] )
EVALUATE
SUMMARIZECOLUMNS (
'Gênero'[Gênero];
'Profissão'[Profissão];
__DS0FILTERTABLE;
__DM3FILTERTABLE;
"VISITAS"; IGNORE 'VISITAS'[# VISITAS];
"GRUPOVISITAS"; IGNORE 'VISITAS'[# GRUPO VISITAS]
)
Portanto, o primeiro passo foi bem-sucedido e a existência automática não está mais em ação aqui. Já sabíamos que essa etapa era necessária, mas isso ainda não é suficiente para resolver o problema.
A linha que falta no nosso relatório é (Masculino, Trainee PBI). Como temos duas dimensões, Profissão e Gênero, sabemos que SUMMARIZECOLUMNS realmente calcula o valor dessa combinação. No entanto, sai em branco. Precisamos investigar mais para determinar o motivo.
Para a combinação Gênero=Masculino, Profissão=Trainee PBI, DAX faz o seguinte cálculo:
Grupo Visitas := CALCULATE(
[# Visitas];
REMOVEFILTERS ( 'Visitas'[Salão] );
VALUES ( 'Visitas'[Grupo] )
)
Portanto, podemos expandir a expressão completa para entendermos melhor o que está acontecendo:
EVALUATE
{
CALCULATE (
CALCULATE (
[# VISITAS];
REMOVEFILTERS ( 'VISITAS'[Salão] );
VALUES ( 'VISITAS'[GRUPO] )
):
'VISITAS'[Salão] = "Izzy & C",
'GÊNERO'[Gênero] = "Masculino",
'Profissão'[Profissão] = "Trainee PBI"
)
}
O CALCULATE interno avalia a função VALUES no contexto de filtro definido pelo CALCULATE externo. Como não há Trainees masculinos visitando Izzy & C, VALUES(‘VISITAS'[Grupo] retorna uma tabela vazia, não uma tabela com o grupo ao qual o salão pertence. Portanto, a medida retorna em branco.
Embora esse comportamento esteja muito próximo de existir automaticamente, desta vez a falha é inteiramente nossa. O DAX não faz parte do cálculo impreciso.
Quando o conjunto de filtros no contexto do filtro produz um resultado vazio, não há como descobrir a qual grupo o salão atual pertence, porque não há linhas na tabela Visitas nos informando isso. Em outras palavras, contamos com a tabela Fato para nos dizer a qual grupo um salão pertence. Na ausência de visitas, a informação não está disponível.
Compreender o problema é muito mais difícil do que encontrar a solução. Para evitar o problema, precisamos definir uma estrutura de dados contendo salões e seus respectivos grupos. Esta tabela não pode ser a tabela Visitas, que pode ser filtrada pelo relatório; precisa ser uma dimensão dedicada. Portanto, o passo final para resolver o cenário é construir uma terceira dimensão para os salões de beleza com uma tabela denominada Salão de Beleza(Salão).
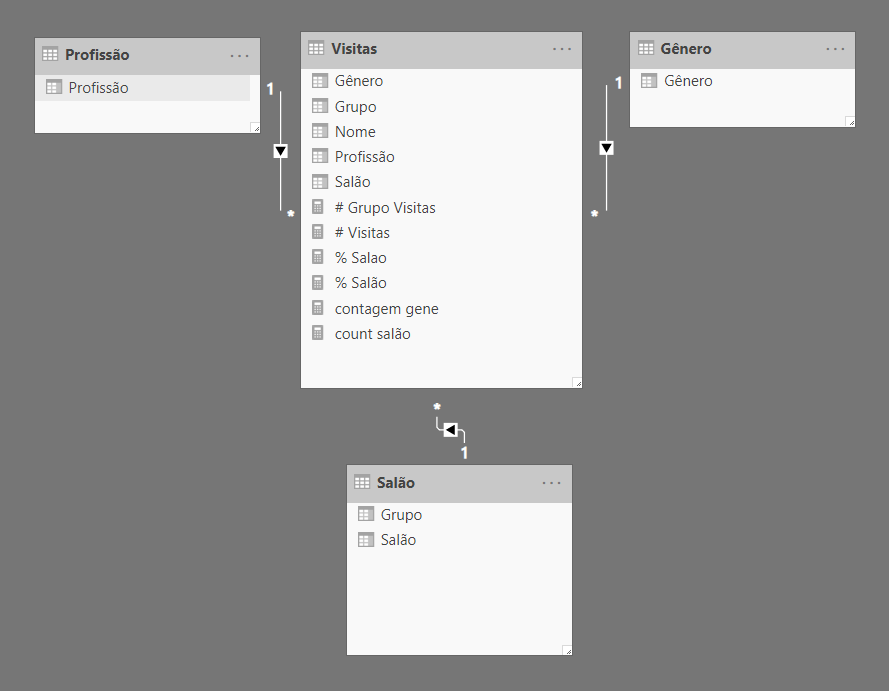
Uma vez que temos a nova dimensão, usamos um slicer com a coluna Salão da tabela Salão, em vez da coluna Salão da tabela Visitas, de depois fazemos uma pequena correção no DAX:
# Grupo Visitas =
CALCULATE(
[# Visitas];
REMOVEFILTERS ( 'Salão'[Salão] );
VALUES ( 'Salão'[Grupo] )
)
Como você viu, as funções REMOVEFILTERS e VALUES operam na dimensão em vez de trabalhar contra as colunas da tabela Fato.
A lógica geral da medida permanece a mesma. Com essa nova medida em vigo, o relatório agora mostra os resultados corretos.

Detectar o problema em um modelo com 10 linhas provou ser um desafio do ponto de vista do DAX, mas foi facilitado pelo fato de sabermos quais números esperar no resultado. Agora, imagine ter que encontrar esse problema em um modelo com milhões de linhas. É por isso que modeladores especialistas sempre seguem estas regras:
- Use um esquema em estrela. SEMPRE.
- Oculte todas as colunas na tabela fato. Mostre apenas medidas.
- Exponha atributos visíveis apenas através das dimensões.
- Teste suas fórmulas em pequenos conjuntos de dados que você pode dominar e entender rapidamente.
Essas são regras de ouro. Os modeladores especialistas podem decidir substituir as regras, mas o fazem com um entendimento profundo do que estão lidando.
Modeladores inexperientes muitas vezes optam por evitar regras. Fazer isso é emocionante, se você quiser sentir a emoção de vagar em um labirinto de complexidade totalmente inexplorado e perigoso, vá em frente(eu já fiz isso, mas é dolorido).
Por outro lado se você deseja implantar um modelo de eficaz para seus clientes, obedecer a essas regras simples é um passo muito bom na direção certa.
Esse artigo foi traduzido do mestre Alberto Ferrari e está no site sqlbi.com.